In the previous post we have seen that GUIDs as primary keys can lead to some serious performance problems. What we need is a primary key that won’t cause excessive I/O on inserts and reduce contention on the right hand side index leaf block. And I like it to be RAC aware.
To build a primary key that addresses above mentioned issue we use three different components:
- the Oracle instance number
- a one (or two) digit number
- Oracle generated sequence number
The Oracle instance number is useful in Real Application Cluster setups to minimize data block transfers between nodes on inserts as each instance has its own part of the index tree to work on.
The one (or two) digit number could be anything that allows for distribution between sessions. For instance “mod(sid, 10)” or “round(dbms_random.value(0, 9), 0)”. The goal here is that each session works on different parts of the index.
The Oracle sequence number makes the key values unique.
I’m going to use the same test setup from the previous post. Tables TESTS and RESULTS are the same except that I changed the data type from “RAW(16)” to “NUMBER(10, 0)”.
create table tests (
test_id number(10, 0) not null
, vc2_long varchar2(4000 byte)
) tablespace myapp_data;
create unique index tests_idx_01 on tests (test_id) tablespace myapp_index;
alter table tests add constraint tests_pk primary key (test_id) using index tests_idx_01;
create table results (
result_id number(10, 0) not null
, test_id number(10, 0) not null
, dt date
, vc2_short varchar2(200 byte)
) tablespace myapp_data;
create unique index results_idx_01 on results(result_id) tablespace myapp_index;
alter table results add constraint results_pk primary key (result_id) using index results_idx_01;
create index results_idx_02 on results(test_id) tablespace myapp_index;
alter table results add constraint results_fk_01 foreign key (test_id) references tests(test_id) on delete cascade;
And we need sequences to get uniqueness.
create sequence tests_seq_pk cache 1000 noorder; create sequence results_seq_pk cache 10000 noorder;
From the table definition above you can see I’m using one single number column to hold the three-part primary key values. As we need the three parts put together in a specific order (instance, some number, sequence) we cannot simply add up the numbers. I’ll use stored functions to concatenate the parts as strings and then cast the result to a number.
create or replace function tests_id_distr
return number
is
begin
return to_number(sys_context('userenv', 'instance') || to_char(mod(sys_context('userenv', 'sid'), 10)) || to_char(tests_seq_pk.nextval) || dummy_java_call);
end tests_id_distr;
/
create or replace function results_id_distr
return number
is
begin
return to_number(sys_context('userenv', 'instance') || to_char(mod(sys_context('userenv', 'sid'), 10)) || to_char(results_seq_pk.nextval || dummy_java_call));
end results_id_distr;
/
What’s the “dummy_java_call” at the end there, you ask?
Well, PL/SQL is blazingly fast 🙂 …and concatenating & casting a few strings and numbers doesn’t do the Java GUID implementation justice. To get fairly comparable results I made this implementation also do a context switch to the JVM for every key generated. The Java method simply returns an empty string (or NULL if you will in the PL/SQL context).
create or replace and compile java source named "DummyJavaCall"
as
public class DummyJavaCall {
public static String create() {
return "";
}
}
/
create or replace function dummy_java_call
return varchar2
is
language java name 'DummyJavaCall.create() return java.lang.String';
/
The test script was just slightly modified to use the new stored functions to get the primary key values. Otherwise it is the same: inserting 1000 Tests in a loop. After each test it inserts 100 Results per Test in the inner loop and commits.
set verify off feedback off
set serveroutput on size unlimited
<<myapp>>
declare
test_id tests.test_id%type;
begin
rrt.stat_cfg_default;
rrt.stat_start('&1');
rrt.timer_start();
for tid in 1 .. 1000 loop
insert into tests t (test_id, vc2_short) values (tests_id_distr(), dbms_random.string('A', trunc(dbms_random.value(200, 4000))))
returning t.test_id into myapp.test_id;
for rid in 1 .. 100 loop
insert into results r (result_id, test_id, dt, vc2_short) values (results_id_distr(), myapp.test_id, sysdate, dbms_random.string('L', trunc(dbms_random.value(10, 200))));
end loop;
commit;
end loop;
dbms_output.put_line('Elapsed:' || to_char(rrt.timer_elapsed));
rrt.stat_stop;
end;
/
exit success
I again used the shell script from the GUID test case to run 10 concurrent session for each run. The VM and database specification is the exact same for both test cases. To get approximately the same data volume for the indexes I had to run this test case 12 times.
RESULTS_IDX_01 is 34 MB bigger as in the GUID test case (385 vs 351 MB)
RESULTS_IDX_02 is 6 MB smaller as in the GUID test case (389 vs 395 MB)
Also the number of leaf blocks are in the same ballpark.
SQL> select segment_name, tablespace_name, blocks, extents, bytes/1024/1024 mb from dba_segments where (segment_name like 'TESTS%' or segment_name like 'RESULTS%') order by segment_name desc; SEGMENT_NAME TABLESPACE_NAME BLOCKS EXTENTS MB --------------- ---------------- ------- -------- ---- TESTS_IDX_01 MYAPP_INDEX 512 4 4 TESTS MYAPP_DATA 41216 322 322 RESULTS_IDX_02 MYAPP_INDEX 49792 389 389 RESULTS_IDX_01 MYAPP_INDEX 49280 385 385 RESULTS MYAPP_DATA 220160 1720 1720
SQL> select table_name, index_name, uniqueness, blevel, leaf_blocks, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key, clustering_factor, num_rows from dba_indexes where index_name in ('TESTS_IDX_01', 'RESULTS_IDX_01', 'RESULTS_IDX_02') order by table_name desc, index_name;
TABLE_NAME INDEX_NAME UNIQUENESS BLEVEL LEAF_BLOCKS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR NUM_ROWS
----------- --------------- ----------- ------- ------------ -------------- ------------------------ ------------------------ ------------------ --------
TESTS TESTS_IDX_01 UNIQUE 1 442 120000 1 1 92579 120000
RESULTS RESULTS_IDX_01 UNIQUE 2 47849 11704420 1 1 1082748 11704420
RESULTS RESULTS_IDX_02 NONUNIQUE 2 49037 118856 1 4 497219 11986476
From this setup the aggregated session statistics show that we constantly get low numbers of physical reads and elapsed times irrespective of the data volume of the underlying tables and indexes.
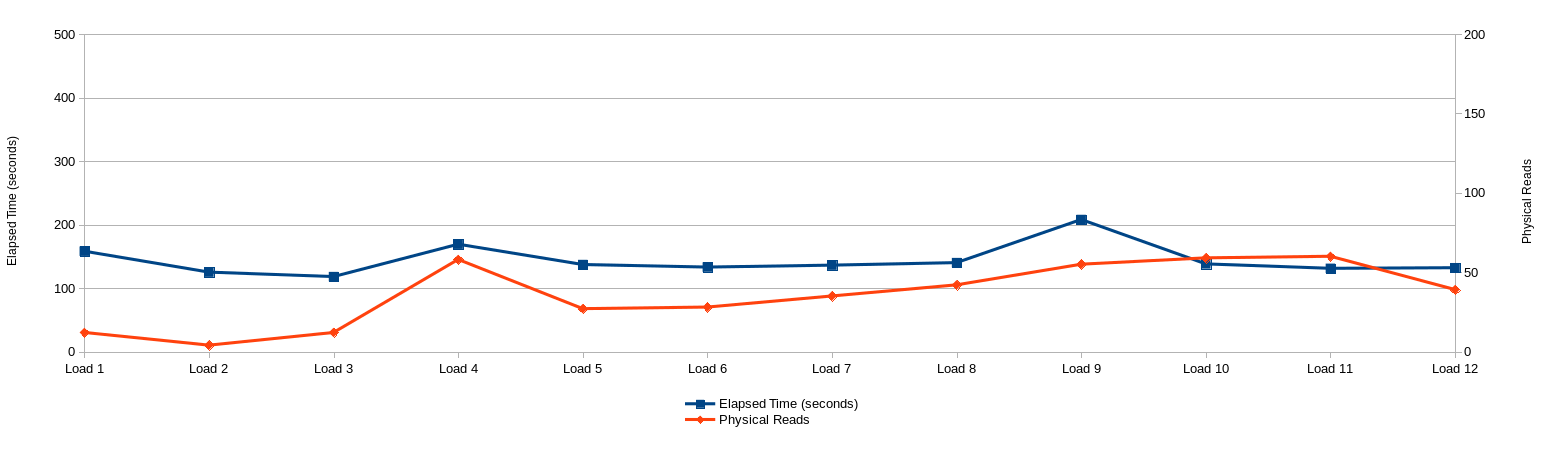
I like this solution because it addresses the scalability issues and doesn’t rely on any fancy Oracle feature (which you might need extra cost options for).