Imagine you run a trading application that, every morning at market open, processes many thousands of orders from a queue using dozens of database connections. And as we all know, trade order processing is a time critical task.
The system is a two node RAC cluster that is backed by a Data Guard physical standby database with the exact same specifications and configuration. To give you an idea what is going on in the database during this peak order processing, here are a few AWR stats (this is from node 1, but node 2 very much looks the same):
Per Second
DB Time(s): 23.7
DB CPU(s): 4.8
Background CPU(s): 0.6
Redo size (bytes): 2,569,543.4
Logical read (blocks): 692,837.9
Block changes: 11,668.0
Physical read (blocks): 463.7
Physical write (blocks): 219.8
Read IO requests: 416.8
Write IO requests: 99.6
Global Cache blocks received: 2,125.3
Global Cache blocks served: 2,368.7
User calls: 9,354.2
Parses (SQL): 6,208.7
Hard parses (SQL): 1.6 0.0
Executes (SQL): 14,642.5
Rollbacks: 6.9 0.0
Transactions: 518.9
This is a fairly busy system with 9000+ user calls and 500+ transactions per second. “DB CPU” is about 1/5 of “DB Time” and with 32 physical cores per node the system certainly is not CPU bound. Below stats are based on a 30 seconds snapshot interval (I know, it’s insanely short but we had our reasons 🙂 ).
Event Waits Total Wait Time (sec) Wait Avg(ms) % DB time Wait Class
log file sync 15,404 244.9 15.90 29.8 Commit
DB CPU 167.9 20.4
gc buffer busy release 2,601 101.1 38.87 12.3 Cluster
gc buffer busy acquire 7,240 81 11.19 9.8 Cluster
gc current block busy 4,662 78.8 16.91 9.6 Cluster
gc cr block busy 3,945 68.7 17.40 8.3 Cluster
cell single block physical read 13,029 12.3 0.94 1.5 User I/O
enq: TX - index contention 653 7.3 11.21 .9 Concurrency
enq: TX - row lock contention 378 5.3 14.08 .6 Application
gc current block 2-way 24,480 4.4 0.18 .5 Cluster
The top 10 waits show that 30% of the time was spent on “log file sync” with almost 16ms average wait time. 16ms for commit latency seems high, let’s take a closer look in the wait event histogram:
Event Waits 64ms to 2s <32ms <64ms <1/8s <1/4s <1/2s <1s <2s >=2s
log file sync 801 94.8 .7 .5 3.7 .2 .2
Most outliers (15404/100*3.7 = 570) are in the 128ms – 250ms bucket . “log file sync” is the wait from the foreground processes and in Oracle 12c the wait chain for Data Guard sync mode is as follows:
"log file sync" (foreground process)
=> "SYNC Remote Write" (LGWR)
=> "Redo Transport MISC" (NSSn)
So let’s see what we have in the wait stats for the background processes:
Event Waits %Time -outs Total Wait Time (s) Avg wait (ms) Waits /txn % bg time
gcs log flush sync 91,603 1 45 0.49 5.09 19.64
Redo Transport MISC 6,335 0 29 4.59 0.35 12.62
SYNC Remote Write 6,335 0 28 4.34 0.35 11.93
log file parallel write 6,297 0 3 0.54 0.35 1.49
gc current block busy 53 0 2 43.59 0.00 1.00
gc buffer busy release 18 0 1 72.30 0.00 0.56
...
While not great, the average for “Redo Transport MISC” is “only” 4.59ms as compared to the 16ms “log file sync”.
Background wait event histogram:
Event Waits 64ms to 2s <32ms <64ms <1/8s <1/4s <1/2s <1s <2s >=2s
Redo Transport MISC 57 99.1 .0 .0 .8 .0 .0
SYNC Remote Write 57 99.1 .0 .0 .8 .0 .0
Same as for “log file sync” most of the outliers for the redo transmission wait events are in the 128ms – 250ms range.
It looks like the redo transmission from primary to standby is sometimes stalling LGWR and thus causing many foreground transactions to wait for LGWR (that’s why the average “log file sync” wait is so much higher).
SQL traces from NSS/RFS processes confirmed that there are around 80-120 outliers per minute. While the redo transmission is on TCP (or lower) the corresponding RFS process on the standby is waiting on “SQL*Net message from client” or “SQL*Net more data from client”.
NSS2 trace:
WAIT #0: nam='Redo Transport MISC' ela= 205429 p1=0 p2=0 p3=0 obj#=-1 tim=12736668661230
corresponding RFS trace:
WAIT #0: nam='SQL*Net message from client' ela= 207662 driver id=1413697536 #bytes=1 p3=0 obj#=-1 tim=18731316629403
This told us that both, the sender and the receiving process were waiting on the network stack and interestingly, in all instances the waits took a just a little over 200ms.
The next thing was running a TCP packet capture (tcpdump) on the primary & standby database servers to see what was going on on the network stack. This revealed that every time we saw a 200ms long “Redo Transport MISC” event in the NSS2 trace a TCP retransmission would occur, e.g.:

Why does it consistently take 200ms before the packet is retransmitted?
There is an exponential back-off algorithm in the Linux kernel for TCP retransmissions and it starts at 200ms in this environment:
$ grep '^CONFIG_HZ' /boot/config-$(uname -r)
CONFIG_HZ_1000=y
CONFIG_HZ=1000
$ grep '#define TCP_RTO_MIN' /usr/src/kernels/$(uname -r)/include/net/tcp.h
#define TCP_RTO_MIN ((unsigned)(HZ/5))
1000 HZ / 5 = 200ms(period). As in this case retransmissions only occur occasionally relative to the total packet volume the back-off algorithm never kicks in and the RTO stays at 200ms.
By the way, the retransmission timeout is calculated per port and the current value can be displayed using the “ss” command. For instance:
$ ss -o -p -n -i sport = :2483
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 0 0 ::ffff:192.168.56.60:2483 ::ffff:192.168.56.1:46218 users:(("oracle_3485_dev",pid=3485,fd=16)) timer:(keepalive,9min52sec,0)
ts sack cubic wscale:7,7 rto:208 rtt:7.382/13.049 ato:40 mss:1448 rcvmss:1448 advmss:1448 cwnd:10 bytes_acked:5897 bytes_received:4860 send 15.7Mbps lastsnd:8237 lastrcv:8238 lastack:8237 pacing_rate 31.4Mbps rcv_rtt:60 rcv_space:28960
tcp ESTAB 0 0 ::ffff:192.168.56.60:2483 ::ffff:192.168.56.1:46086 users:(("oracle_2024_dev",pid=2024,fd=16)) timer:(keepalive,4min45sec,0)
ts sack cubic wscale:7,7 rto:212 rtt:11.107/15.77 ato:40 mss:1448 rcvmss:1448 advmss:1448 cwnd:10 bytes_acked:7009 bytes_received:7710 send 10.4Mbps lastsnd:1515530 lastrcv:1515611 lastack:315015 pacing_rate 20.9Mbps rcv_rtt:54 rcv_space:28960
You can see one port has RTO=208 and the other is RTO=212 but they are all close to 200ms.
What can we do about it?
Well, ideally you want no TCP retransmissions to occur in your network but that’s just not going to happen, after all TCP was designed to deal with lossy networks. In this system the retransmissions make less than 0.1% of all the Data Guard traffic, nevertheless the impact on the trading application is real. Since TCP_RTO_MIN and the back-off algorithm are hard-wired into the Linux kernel I only know of one way to change the minimum RTO:
Setup a separate network route for the Data Guard traffic (if you haven’t already for other reasons) and set the RTO on the IP route level:
ip route change <dest> dev <device> proto kernel scope link src <IP> \
rto_min 10ms
With that retransmissions happen after 10ms instead of 200ms which mitigates the impact on LGWR and the foreground processes waiting for the redo data to be shipped. How low you can set the RTO depends on your network characteristics and you may need to dial in the value not to cause extra retransmissions.
ss -o -p -n -i sport = :2483
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 0 0 ::ffff:192.168.56.60:2483 ::ffff:192.168.56.1:45430 users:(("oracle_1651_dev",pid=1651,fd=16)) timer:(keepalive,9min52sec,0)
ts sack cubic wscale:7,7 rto:11 rtt:0.303/0.43 ato:40 mss:1448 rcvmss:1448 advmss:1448 cwnd:10 bytes_acked:5897 bytes_received:4860 send 382.3Mbps lastsnd:5082 lastrcv:5421 lastack:5082 pacing_rate 764.3Mbps retrans:0/2 rcv_rtt:31 rcv_space:28960
tcp ESTAB 0 0 ::ffff:192.168.56.60:2483 ::ffff:192.168.56.1:45438 users:(("oracle_1655_dev",pid=1655,fd=16)) timer:(keepalive,9min54sec,0)
ts sack cubic wscale:7,7 rto:11 rtt:0.291/0.334 ato:40 mss:1448 rcvmss:1448 advmss:1448 cwnd:10 bytes_acked:5896 bytes_received:4860 send 398.1Mbps lastsnd:5082 lastrcv:5556 lastack:5082 pacing_rate 794.1Mbps retrans:0/2 rcv_rtt:69 rcv_space:28960
Thanks to the IP route configuration the socket level RTO now starts at 10ms (actually at 11ms in above example).
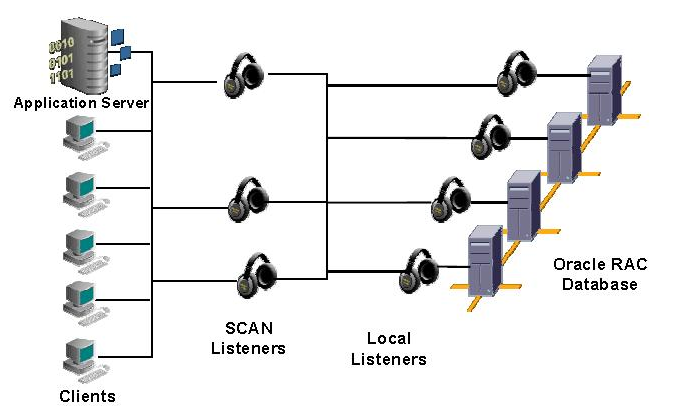
For single instance the setup is fairly simple, for RAC you need to provision an additional set of SCAN listeners.
To make the route change persistent across OS reboot I use a oneshot systemd unit.