Who doesn’t want to write scalable applications these days? Then maybe you should think twice about using GUIDs as primary keys. It’s mostly not about storage overhead, or the fact that surrogate keys are not always the best solution. It is about performance!
I’m going to talk about Oracle here in particular but most of the concepts are the same/or similar in other database systems.
Usually, you’re using B-tree indexes and unique constraints to police primary keys. And if you read the excellent book SQL Performance Explained by Markus Winand you might already know what pain you’ll be facing by using GUIDs. As long as your data volume is tiny and can fully live in the buffer cache you’re probably fine. To illustrate what happens once your dataset outgrows the buffer cache I setup a small test kit.
The data model is simple. I have two tables, TESTS and RESULTS. Each Test has zero or more Results. To store GUIDs I will use data type RAW(16). The rest of the columns will hold random data to fill the space.
create table tests (
test_id raw(16) not null
, vc2_long varchar2(4000 byte)
) tablespace myapp_data;
create unique index tests_idx_01 on tests (test_id) tablespace myapp_index;
alter table tests add constraint tests_pk primary key (test_id) using index tests_idx_01;
create table results (
result_id raw(16) not null
, test_id raw(16) not null
, dt date
, vc2_short varchar2(200 byte)
) tablespace myapp_data;
create unique index results_idx_01 on results(result_id) tablespace myapp_index;
alter table results add constraint results_pk primary key (result_id) using index results_idx_01;
create index results_idx_02 on results(test_id) tablespace myapp_index;
alter table results add constraint results_fk_01 foreign key (test_id) references tests(test_id) on delete cascade;
For ease of grep’ing SQL traces I separated tables and indexes to different Tablespaces. MYAPP_INDEX has one datafile with file# 20.
I wanted to use PL/SQL to keep the test case short and concise. Unfortunately, Oracle’s SYS_GUID function produces “sequential” GUIDs in my setup (Oracle 12.2 CDB on Oracle Linux 7.2). To have random GUIDs in PL/SQL I resorted to Java stored procedures (the implementation is not relevant to the case at hand):
create or replace and compile java source named "RandomGUID"
as
public class RandomGUID {
public static String create() {
return java.util.UUID.randomUUID().toString().replaceAll("-", "").toUpperCase();
}
}
/
create or replace function random_java_guid
return varchar2
is
language java name 'RandomGUID.create() return java.lang.String';
/
create or replace function random_guid
return raw
is
begin
return hextoraw(random_java_guid());
end random_guid;
/
Works like a charm 🙂
select random_guid() guids from dual connect by level <= 5; GUIDS -------------------------------- 54746B0750374133BCF9FA85A6F2F532 C92168647BEC4A93982F19498238757E 3E4B858F41764126B177FCCB30CC73C5 4B7CD39D222D4E339482CD25F9AD6EA2 B8C5367F6B944EEA9BD71611CCB54E72
That’s it for the schema setup. To load data I use below code snippet (test1.sql) which in a loop inserts 1000 Tests. After each test it inserts 100 Results per Test in the inner loop and commits. The “RRT” package is used to collect session statistics (gv$session) and tracking wall clock time.
set verify off feedback off
set serveroutput on size unlimited
<<myapp>>
declare
test_id tests.test_id%type;
begin
rrt.stat_cfg_default;
rrt.stat_start('&1');
rrt.timer_start();
for tid in 1 .. 1000 loop
insert into tests t (test_id, vc2_long) values (random_guid(), dbms_random.string('A', trunc(dbms_random.value(200, 4000))))
returning t.test_id into myapp.test_id;
for rid in 1 .. 100 loop
insert into results r (result_id, test_id, dt, vc2_short) values (random_guid(), myapp.test_id, sysdate, dbms_random.string('L', trunc(dbms_random.value(10, 200))));
end loop;
commit;
end loop;
dbms_output.put_line('Elapsed:' || to_char(rrt.timer_elapsed));
rrt.stat_stop;
end;
/
To run the script concurrently in multiple sessions I use following shell script. It just spawns N SQL*Plus processes and runs the SQL script.
#!/usr/bin/bash
SCRIPT=$1
DEGREE=$2
EZCONN=$3
declare -i runid=$$
declare -i cnt=1
echo "Coordinator process pid ${runid}"
until [ $cnt -gt ${DEGREE} ]
do
sqlplus -S -L ${EZCONN} @${SCRIPT} ${SCRIPT}.${runid}.${cnt}.log > ${SCRIPT}.${runid}.${cnt}.log &
echo "Started sub-process ${cnt} with pid $!"
cnt=$(( cnt + 1 ))
done
I ran the test case multiple times letting the database grow bigger with every run. I kept running until the performance got unbearable. On my VirtualBox VM setup it took 9 runs with 10 concurrent processes for the performance to go way down south. I deliberately configured a small SGA of 800 MB which resulted in about 500 MB buffer cache to hit the issue soon. Obviously, your milage may vary as the larger the buffer cache the longer you can sustain.
Let’s look at resource usage profile of one of the sessions from run 9. I processed the raw extended SQL trace file using Chris Antognini’s TVD$XTAT.
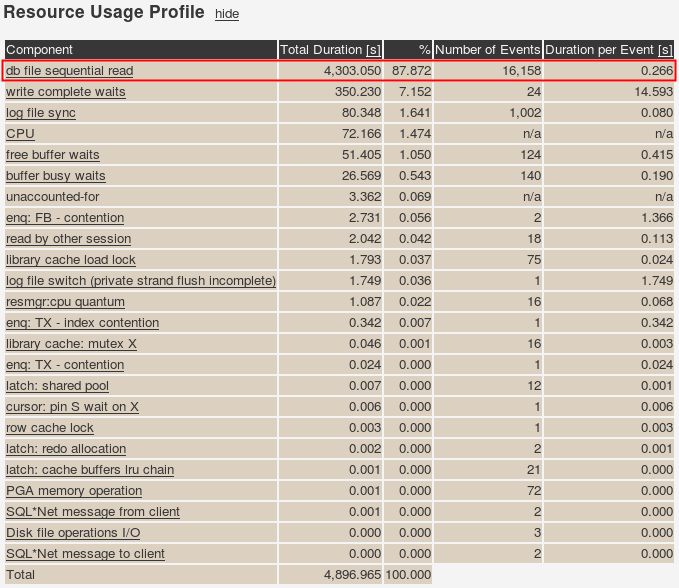
Wow, this single session did 16,158 random physical reads (db file sequential read). Let’s see which statements contributed to those reads:
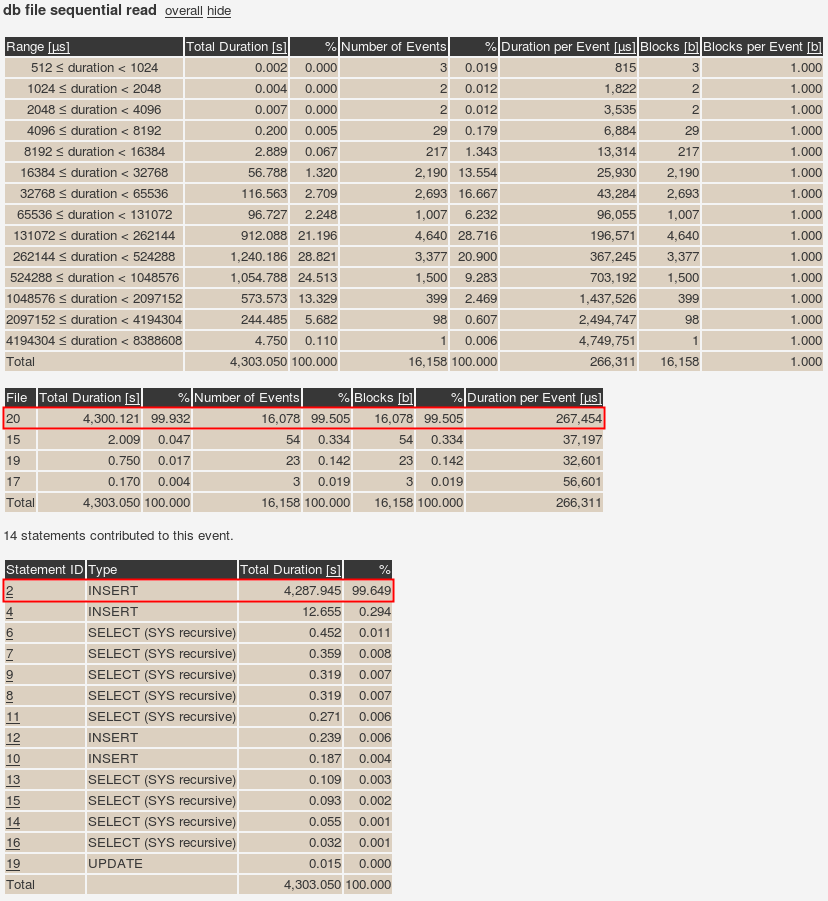
Almost all of the random reads (16,078) came from the INSERT statement with ID 2 which is:

All this physical read I/O to INSERT records, which is all this test case does. And as you can see above the I/O is done on file 20 from the MYAPP_INDEX Tablespace. What’s the distribution between objects?
$ grep 'db file.*file#=20' *ora_5592.trc | cut -d ' ' -f12 | sort | uniq -c
42 obj#=61805
14538 obj#=61807
1498 obj#=61808
select object_id, object_name from cdb_objects where con_id = 4 and owner = 'MYAPP' and object_id in (61805, 61807, 61808) order by object_id;
OBJECT_ID OBJECT_NAME
---------- ---------------
61805 TESTS_IDX_01
61807 RESULTS_IDX_01
61808 RESULTS_IDX_02
Considering the data pattern it makes sense that RESULTS_IDX_01 is suffering the most. It is the unique index that gets the most index entries added. Index RESULTS_IDX_02 benefits from the repeating foreign key values per outer-loop that all go into the same leaf blocks which Oracle most likely caches.
select table_name, index_name, uniqueness, blevel, leaf_blocks, distinct_keys, avg_leaf_blocks_per_key, avg_data_blocks_per_key, clustering_factor, num_rows from dba_indexes where index_name in ('TESTS_IDX_01', 'RESULTS_IDX_01', 'RESULTS_IDX_02') order by table_name desc, index_name;
TABLE_NAME INDEX_NAME UNIQUENESS BLEVEL LEAF_BLOCKS DISTINCT_KEYS AVG_LEAF_BLOCKS_PER_KEY AVG_DATA_BLOCKS_PER_KEY CLUSTERING_FACTOR NUM_ROWS
----------- --------------- ----------- ------- ------------ -------------- ------------------------ ------------------------ ------------------ --------
TESTS TESTS_IDX_01 UNIQUE 1 467 90000 1 1 89999 90000
RESULTS RESULTS_IDX_01 UNIQUE 2 44237 8941107 1 1 8941107 8941107
RESULTS RESULTS_IDX_02 NONUNIQUE 2 50757 92216 1 4 424304 9137794
Up to test run 8 Oracle could keep the most relevant parts of the indexes in the buffer cache. After that Oracle had to constantly “swap” index leaf blocks in and out of the buffer cache.
select segment_name, tablespace_name, blocks, extents, bytes/1024/1024 mb from dba_segments where (segment_name like 'TESTS%' or segment_name like 'RESULTS%') order by segment_name desc; SEGMENT_NAME TABLESPACE_NAME BLOCKS EXTENTS MB --------------- ---------------- ------- -------- ---- TESTS_IDX_01 MYAPP_INDEX 512 4 4 TESTS MYAPP_DATA 31360 245 245 RESULTS_IDX_02 MYAPP_INDEX 50560 395 395 RESULTS_IDX_01 MYAPP_INDEX 44928 351 351 RESULTS MYAPP_DATA 191744 1498 1498
I also graphed the session statistics aggregated (average of the 10 concurrent sessions) by test runs. It clearly shows a correlation between physical reads and elapsed time. Who’d a thunk it? 🙂
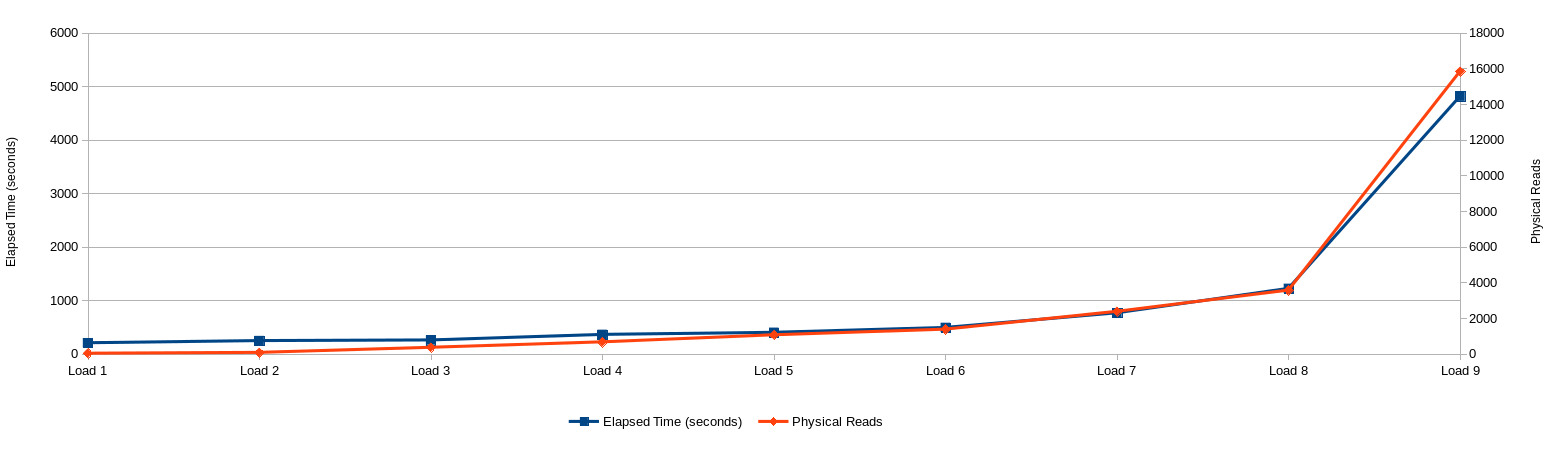
Due to the random character of GUIDs every new index entry potentially goes into any of the index leaf blocks. Thus, performance is good as long as you can cache the entire index, meaning every index supporting primary and foreign keys in you entire application. That’s probably too much to ask.
Now, you might know about sequential GUIDs that Oracle and SQL Server implement and start using them. This might alleviate the problem somewhat, but could result in the next performance issue: right hand side index leaf block contention!
As this post is getting long already I will talk about a solution that scales in my next installment.
Pingback: Scalable primary keys (GUID follow-up) | Spot on Oracle